Predicting Building Energy Consumption Analysis Using Support Vector Machine

Predicting building energy consumption analysis using Support vector machine
As we as a whole realize energy assumes a significant job in the cutting edge world so it guarantees human accommodation and advancement of the nations. Right now, the reasons for electric utilization’s fast development incorporate colossally expanded human population, structures, and innovation application building vitality utilization and efficiency.
The regularly expanding human populace, building developments, and innovation uses have as of now made electric utilization develop significantly. As needs be, a portion of the efficient devices for increasingly more vitality sparing and improvement are efficient energy management systems and anticipating vitality utilization for structures. Furthermore, efficient vitality of the board what’s more, shrewd rebuilding can improve vitality execution in different territories. Given that electricity is the primary type of energy that is devoured in private structures, estimating the electrical energy utilization in a structure will bring significant benefits to the structure and entrepreneurs. In late years, artificial intelligence and machine learning methods, in certain zones, have been utilized to estimate building vitality utilization and efficiency.
Factual reports (World Energy Trilemma Index 2018) show that the example of populace development ceaselessly ascends in many created nations. The developing example of the human populace prompts the expanded structure vitality utilization that is increasingly evident in the modern field. Looked at populace development just as the interest for vitality required for human survival, numerous difficulties will emerge for extended or creating nations. However, to decrease contamination, carbon emanation, and nursery effect, ecological subjects must be considered in the improvement procedure. A significant change in human vitality utilization, greater condition amicable items, and distinguishing are required to arrive at decreased ozone-depleting substances. As per Global Energy Statistical Yearbook 2018 (World Power Consumption 2019), because of electrification of energy utilizes, electricity utilization builds quicker contrasted with different sorts of energy. Asia experienced most power utilization increment in 2017.
Unmistakably in calm areas, the cooling framework utilizes less power. Notwithstanding temperature, some different factors additionally intrigue the power request that among them stickiness, wind speed, darkness, rainfalls also, sun oriented radiation can be referenced. Moreover, the diverse working long periods of different structures can be referenced as far as time-scale. For instance, the power utilization term is generally 24 h in modern structures. For office structures, the working time is normally set with the specified time interim. In a private spot, the most extreme power use is in the evening. Be that as it may, this electrical vitality use likewise depends on a few conditions, for example, occasions, seasons travel, cataclysmic events, and others. As of now, many estimating models have been introduced utilizing a few strategies to settle anticipating complexities and to arrive at most extreme estimating exactness. There are a few well known approaches to conjecture building vitality utilization, partitioned into four principle classifications in particular building count, recreation model based, measurable displaying and Artificial knowledge strategy (Melody et al. 2017; Seyedzadeh et al. 2018). The designing procedures utilize physical laws to get building vitality utilization in entire or sub-framework levels. These strategies have complex computations for different building parts and their information sources are inside and outer subtleties. In a reproduction model system, programming and PC models are utilized for execution reproduction with predefined conditions. PC recreation makes a framework which uses a PC to recreate a scientific model (Nowotarski et al. 2018). Truth be told, PC reenactment has numerous applications including climate determining, cost determining on financial markets, reenactment of electrical circuits, and so on. At last, in a factual strategy, numerical recipes, models and methods are utilized for crude information examination. For the most part, factual strategies extricate data from information and make different approaches to decide the yield exactness. Likewise, in a factual technique, building authentic information are utilized and relapse is as often as possible utilized to show the vitality utilization in structures. Artificial Intelligence (Simulated intelligence) is a wide science field that utilizations picking up, thinking, also, self-modification to take care of issues (Wang et al. 2018). Thus, AI techniques give the capacity to gain from information utilizing a PC calculation. Artificial insight is a more extensive idea of machines having the option to complete assignments

in a shrewd manner. AI (ML) is a far reaching utilization of artificial knowledge that utilizations measurable procedures to enable PC frameworks to gain from information. Among these techniques, the most reasonable actualized technique in estimating is the ML strategy, called bolster vector machine (SVM). Especially, a SVM incorporates regulated learning models with related learning calculations that examinations information utilized for classification and relapse investigation.
Support Vector Machine
The support vector machine (SVM) which was proposed by Vladimir Naumovich Vapnik is a kind of statistical learning method (Vapnik 1999). SVM have special benefits for data types with very high dimensions relative to the observations. So far, SVM has been extensively employed in numerous analyses including regression, classification, and nonlinear function approximation. Support vector regression which is used in the regression problem as an SVM application is suitable for a finite sample regression. It also has an outstanding generalization capability in the regression. SVM algorithm fits a boundary to a region of points which are called a hyper plane. Furthermore, the SVM tries to find the optimal hyper plane which separates two classes by maximizing the distance between the margin of the hyper plane and the data points in the dataset. In other words, given labeled training data while the algorithm output is an optimal hyper plane which categorizes new examples. A training set T = { (xi , yi )|i = 1, 2, …, l } , where the xi ∈ Rn are the input variables and yi ∈ Rn is the corresponding output value. As mentioned earlier, solving non-linear problems is one of the significant benefits of SVM algorithm (Wang and Pardalos 2014). In SVR, the support vectors are separated from the other training observations by a discriminating loss function.
In machine learning, support-vector machines (SVMs, also support-vector networks[1]) are supervised learning models with associated learning algorithms that analyze data used for classification and regression analysis. Given a set of training examples, each marked as belonging to one or the other of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other, making it a non-probabilistic binary linear classifier (although methods such as Platt scaling exist to use SVM in a probabilistic classification setting). An SVM model is a representation of the examples as points in space, mapped so that the examples of the separate categories are divided by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on the side of the gap on which they fall.
In addition to performing linear classification, SVMs can efficiently perform a non-linear classification using what is called the kernel trick, implicitly mapping their inputs into high-dimensional feature spaces.
When data is unlabelled, supervised learning is not possible, and an unsupervised learning approach is required, which attempts to find natural clustering of the data to groups, and then map new data to these formed groups. The support-vector clustering algorithm, created by Hava Siegelmann and Vladimir Vapnik, applies the statistics of support vectors, developed in the support vector machines algorithm, to categorize unlabeled data, and is one of the most widely used clustering algorithms in industrial applications.
Background
Previous research has proven that empirical modeling can provide prominent prediction results and outperforming engineering-based building energy modeling when the learning algorithm was wisely chosen and well utilized [17] [14]. However, some algorithms used in empirical modeling, e.g. DT and ANN, are suspected to be unreliable due to their instability issues [18]. The instability of these algorithms may introduce significant variations in the output due to small changes made in the input data [18], therefore making the prediction results dramatically different from the observed. This can cause the failure of the prediction model. This limitation could impede these algorithms from real world application because many energy efficient measurements, such as building system fault detection and building energy benchmarking, rely on the reliability of the energy prediction results. Moreover, with the development of building energy management technology, buildings nowadays have abundant energy-related data. The short-term building energy prediction has become increasingly important in recent years because of the invention and implementation of high sampling frequency sensors. The prediction accuracy requirements for building energy prediction are becoming more rigid as the building industry pays more attention to the details of building operation and the data. To overcome the instability of the learning algorithm as well as to improve prediction accuracy, more advanced data mining technique called Support vector machine. SVMs are widely used in pattern recognition. Applications in Bioinformatics are numerous, for example protein homology detection and gene expression data categorization from DNA microarrays. Joachims uses SVMs to perform text categorization. Dumas applies SVMs to expression recognition, comparing their performance to a neural network approach operating on the same data, presented by Dailey et al., and reports high recognition rates.
Problem Statement
In recent years, massive quantities of business and research data have been collected and stored, partly due to the plummeting cost of data storage. Much interest has therefore arisen in how to mine this data to provide useful information. Data mining as a discipline shares much in common with machine learning and statistics, as all of these endeavours aim to make predictions about data as well as to better understand the patterns that can be found in a particular dataset. The support vector machine (SVM) is a current machine learning technique that performs quite well in solving common data mining problems.-
As of late, monstrous amounts of business and research information have been gathered and stored, halfway because of the diving cost of information stockpiling. Much intrigue has thusly emerged in how to mine this information to give valuable data. Information mining as a control imparts much in like manner to AI and measurements, as these undertakings mean to cause expectations about information just as to better to comprehend the examples that can be found in a specific dataset. The help vector machine (SVM) is a present AI procedure that performs very well in taking care of normal information mining issues. As we have seen, SVMs relies upon directed learning calculations. The point of utilizing SVM is to accurately group concealed information. SVMs have various applications in a few fields.
Some basic uses of SVM are-
Face location – SVM arrange portions of the picture as a face and non-face and make a square limit around the face.
Content and hypertext order – SVMs permit Text and hypertext classification for both inductive and transductive models. They use preparing information to group archives into various classifications. It arranges based on the score created and after that contrasts and the limit esteem.
Grouping of pictures – Use of SVMs gives better inquiry precision to picture characterization. It gives better exactness in contrast with the conventional inquiry based looking through systems.
Bioinformatics – It incorporates protein order and disease characterization. We use SVM for distinguishing the order of qualities, patients based on qualities and other organic issues.
Handwriting recognition– We use SVMs to perceive written by hand characters utilized generally.
Generalized predictive control (GPC) – Use SVM based GPC to control disorganized elements with valuable parameters.
Literature Review
1) Hamed Tabrizchi et al. 2019 proposed the MVO-SVM approach for foreseeing vitality utilization in private structures. In this study aims to predict energy consumption with higher accuracy
and lower run time .The proposed methodology analyzed a UCI vault dataset. In view of the exploratory outcomes MVO can successfully diminish the quantity of highlights while saving an extraordinary foreseeing accuracy.
2) Amir Mosavi et al. 2019 further infers that there is an extraordinary ascent in the precision, vigor, accuracy and speculation capacity of the ML models in vitality frameworks utilizing half and half ML models. Hybridization is accounted for to be viable in the progression of expectation models, especially for sustainable power source frameworks, e.g., sunlight based vitality, wind vitality, and bio fills. Moreover, the vitality request forecast utilizing half and half models of ML have exceptionally added to the vitality effectiveness and in this way vitality administration and manageability.
3) Subodh Paudel et al. 2015 proposes an expectation model for structure vitality utilization utilizing support vector machine (SVM). Information driven model, for example, SVM is delicate to the determination of preparing information. Along these lines the applicable days information determination technique dependent on Dynamic Time Warping is utilized to prepare SVM model. What’s more, to incorporate warm inactivity of structure, pseudo powerful model is connected since it considers data of progress of energy utilization impacts and occupancy profile.
4) A.S.Ahmad et al. 2014 proposed the building electrical energy forecasting utilizing artificial intelligence (AI) methods, for example, support vector machine (SVM) and artificial neural systems (ANN). The two techniques are generally utilized in the field of estimating and their point on finding the most exact methodology is regularly preceding .Besides the effectively existing single method for forecasting, the hybridization of the two estimating techniques can possibly be connected for increasingly precise outcomes. Further research works are at present on going, regarding the capability of half and half technique for Group Method of Data Handling (GMDH) and Least Square Support Vector Machine (LSSVM), or known as GLSSVM, to gauge building electrical energy utilization.
Objective
The objectives of the proposed research plan are:
1) An objective of building energy performance is crucial for performance assessment and rational decision making on energy retrofits and policies of existing buildings.
2) For building energy analysis we preferred support vector machine tool.
3) Considering the state of the data from energy consumption monitoring platform in public buildings, a hierarchical data processing method is proposed.
TOOLS TO BE USED
The notebook extends the console-based approach to interactive computing in a qualitatively new direction, providing a web-based application suitable for capturing the whole computation process: developing, documenting, and executing code, as well as communicating the results. The Jupyter notebook combines two components:
A web application: a browser-based tool for interactive authoring of documents which combine explanatory text, mathematics, computations and their rich media output.
Notebook documents: a representation of all content visible in the web application, including inputs and outputs of the computations, explanatory text, mathematics, images, and rich media representations of objects.
Proposed methodology
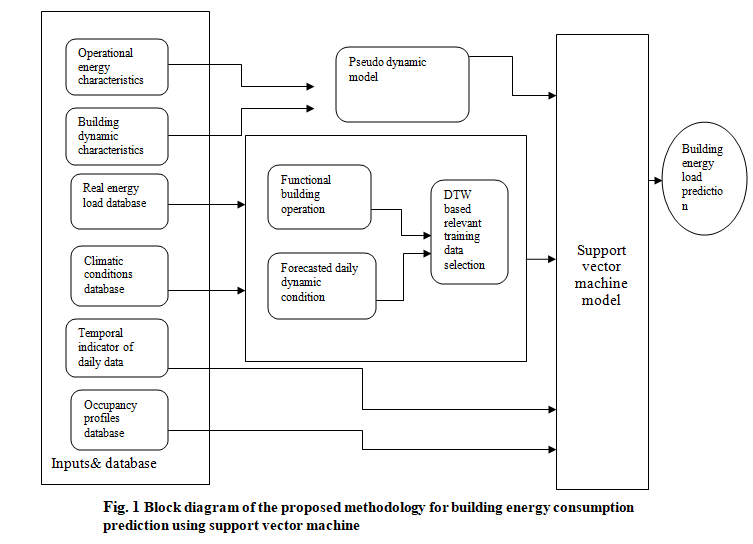
The initial steps of methodology are the collection of building energy consumption data with several climatic variables database and approximate occupancy profile. This input is in the form of time series data. Block diagram of the proposed methodology for building energy consumption prediction using support vector machine is shown in Figure (1).In fig DTW is a distance measure time series algorithm. Input to the methodology is operational energy load characteristics and dynamics of building which are further input to pseudo dynamic model. This pseudo dynamic model considers itself information about transition information of energy load characteristics, occupancy profile and thermal inertia of buildings, which is not fully dynamic but pretend to be dynamic[6].
The steps of SVM to predict the target are as follows-
- Firstly, transform data to the specific format. If the data instance stands for one certain categorical attribute, it needs to be converted into numeric data.
- Secondly, conduct the scaling on the data. The purpose is reducing the difficulty of data processing and calculation.
Thirdly, select the kernel function. For typical kernel function, it includes linear function, polynomial function, radial basis function (RBF), and sigmoid function.
References
- Hamed Tabrizchi,Mohammad Masoud Javidi, Vahid Amirzadeh “Estimates of residential building energy consumption usinga multi‑verse optimizer‑based support vector machine with k‑fold cross‑validation” 2019. [Online]. Available” https://doi.org/10.1007/s12530-019-09283-8”.
- Zhijian Liu1 , DiWu1, Yuanwei Liu1, Zhonghe Han1, Liyong Lun2, Jun Gao3, Guangya Jin1 and Guoqing Cao “Accuracy analyses andmodel comparison ofmachine learning adoptedin building energy consumption prediction” 2019.
- Subodh Paudela, Phuong H. Nguyenb, Wil L. Klingb, Mohamed Elmitric, Bruno Lacarrièrea, and Olivier Le Correa”Support Vector Machine in Prediction of Building Energy Demand Using Pseudo Dynamic Approach” 2015.
- S.Ahmad , M.Y.Hassan , M.P.Abdullah , H.A.Rahman ,F.Hussin , H.Abdullah , R.Saidur “A review on applications of ANN and SVM for building electrical energy consumption forecasting”2014.
- Ximing Wang ,Panos M. Pardalos “A Survey of Support Vector Machines with Uncertainties” 2015.
- Paudel, S., Elmtiri, M., Kling, W.L., Lacarrière, B., Le Corre, O., 2014. Pseudo dynamic transitional modeling of building heating energy demand using artificial neural network. Energy and Buildings 70, 81-93.
- Kadir Amasyali and Nora El-Gohary, Predicting Energy Consumption of Office 83 Buildings: A Hybrid Machine Learning-Based Approach 2018.